
Унифицированная память, интегрируемые библиотеки и другие новшества для разработчиков приложений с GPU-ускорением
САНТА-КЛАРА, Калифорния—14 ноября, 2013— NVIDIA представила новую, 6-ую версию самой популярной в мире платформы параллельных вычислений и модели программирования NVIDIA® CUDA®.
Платформа CUDA 6 максимально упрощает параллельное программирование, позволяя разработчикам значительно сократить время и усилия на создание научных, инженерных, корпоративных и других приложений с помощью графических процессоров.
Платформа обеспечивает новые возможности, позволяющие разработчикам мгновенно ускорять приложения до 8 раз путем замены существующих библиотек на базе CPU. Ключевые возможности CUDA 6:
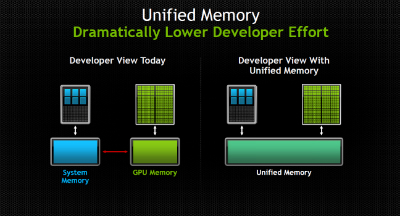
· Унифицированная память – упрощает программирование, обеспечивая приложениям доступ к памяти CPU и GPU без необходимости вручную копировать данные с одной памяти в другую, а также упрощает добавление поддержки GPU-ускорения в широком спектре языков программирования.
· Интегрируемые библиотеки – автоматически ускоряют вычисления BLAS и FFTW в приложениях до 8 раз путем простой замены существующих библиотек CPU на GPU-ускоряемые эквиваленты.
· Многопроцессорное масштабирование. Измененные GPU-библиотеки BLAS и FFT автоматически масштабируют производительность системы при добавлении до 8 GPU, обеспечивая скорость вычислений двойной точности более 9 терафлопс, а также поддерживают еще большие нагрузки (до 512 ГБ). Многопроцессорное масштабирование также можно использовать с новой библиотекой BLAS .
«Благодаря автоматическому управлению данными унифицированная память позволяет нам быстрее моделировать ядра, работающие на GPU, и упрощает код, сокращая время разработки до 50%, - говорит Роб Хоикстра (Rob Hoekstra), директор отделения по масштабируемым алгоритмам при Sandia National Laboratories. – Новые возможности будут очень кстати при выборе модели программирования в будущем и портировании более сложных и громоздких кодов на графические процессоры».
«Наши технологии помогли крупных студиям, разработчикам игр и дизайнерам в создании визуально привлекательных 3D-анимаций и эффектов, - говорит Поль Дойль (Paul Doyle), генеральный директор Fabric Engine. – Наши заказчики уже давно просили добавить в приложения ускорение на GPU, но управление памятью являлось узким местом при работе со сложными проектами. Унифицированная память автоматизирует процесс, направляя компилятор Fabric на графические процессоры NVIDIA, и ускоряет работу приложений наших клиентов до 10 раз».
Помимо вышеперечисленных возможностей платформа CUDA 6 включает полный набор инструментов программирования, GPU-ускоренные математические библиотеки, документы и инструкции по программированию.
Шестая версия Toolkit CUDA будет представлена в начале 2014 года. Разработчики, зарегистрированные в программе CUDA-GPU Computing, будут извещены о ее доступности. Зарегистрироваться в программе можно здесь.
Подробнее о платформе CUDA 6 можно узнать на стенде NVIDIA №613 на конференции SC13, которая пройдет с 18 по 21 ноября в Денвере, а также на сайте NVIDIA CUDA.
САНТА-КЛАРА, Калифорния—14 ноября, 2013— NVIDIA представила новую, 6-ую версию самой популярной в мире платформы параллельных вычислений и модели программирования NVIDIA® CUDA®.
Платформа CUDA 6 максимально упрощает параллельное программирование, позволяя разработчикам значительно сократить время и усилия на создание научных, инженерных, корпоративных и других приложений с помощью графических процессоров.
Платформа обеспечивает новые возможности, позволяющие разработчикам мгновенно ускорять приложения до 8 раз путем замены существующих библиотек на базе CPU. Ключевые возможности CUDA 6:
· Унифицированная память – упрощает программирование, обеспечивая приложениям доступ к памяти CPU и GPU без необходимости вручную копировать данные с одной памяти в другую, а также упрощает добавление поддержки GPU-ускорения в широком спектре языков программирования.
· Интегрируемые библиотеки – автоматически ускоряют вычисления BLAS и FFTW в приложениях до 8 раз путем простой замены существующих библиотек CPU на GPU-ускоряемые эквиваленты.
· Многопроцессорное масштабирование. Измененные GPU-библиотеки BLAS и FFT автоматически масштабируют производительность системы при добавлении до 8 GPU, обеспечивая скорость вычислений двойной точности более 9 терафлопс, а также поддерживают еще большие нагрузки (до 512 ГБ). Многопроцессорное масштабирование также можно использовать с новой библиотекой BLAS .
«Благодаря автоматическому управлению данными унифицированная память позволяет нам быстрее моделировать ядра, работающие на GPU, и упрощает код, сокращая время разработки до 50%, - говорит Роб Хоикстра (Rob Hoekstra), директор отделения по масштабируемым алгоритмам при Sandia National Laboratories. – Новые возможности будут очень кстати при выборе модели программирования в будущем и портировании более сложных и громоздких кодов на графические процессоры».
«Наши технологии помогли крупных студиям, разработчикам игр и дизайнерам в создании визуально привлекательных 3D-анимаций и эффектов, - говорит Поль Дойль (Paul Doyle), генеральный директор Fabric Engine. – Наши заказчики уже давно просили добавить в приложения ускорение на GPU, но управление памятью являлось узким местом при работе со сложными проектами. Унифицированная память автоматизирует процесс, направляя компилятор Fabric на графические процессоры NVIDIA, и ускоряет работу приложений наших клиентов до 10 раз».
Помимо вышеперечисленных возможностей платформа CUDA 6 включает полный набор инструментов программирования, GPU-ускоренные математические библиотеки, документы и инструкции по программированию.
Шестая версия Toolkit CUDA будет представлена в начале 2014 года. Разработчики, зарегистрированные в программе CUDA-GPU Computing, будут извещены о ее доступности. Зарегистрироваться в программе можно здесь.
Подробнее о платформе CUDA 6 можно узнать на стенде NVIDIA №613 на конференции SC13, которая пройдет с 18 по 21 ноября в Денвере, а также на сайте NVIDIA CUDA.


